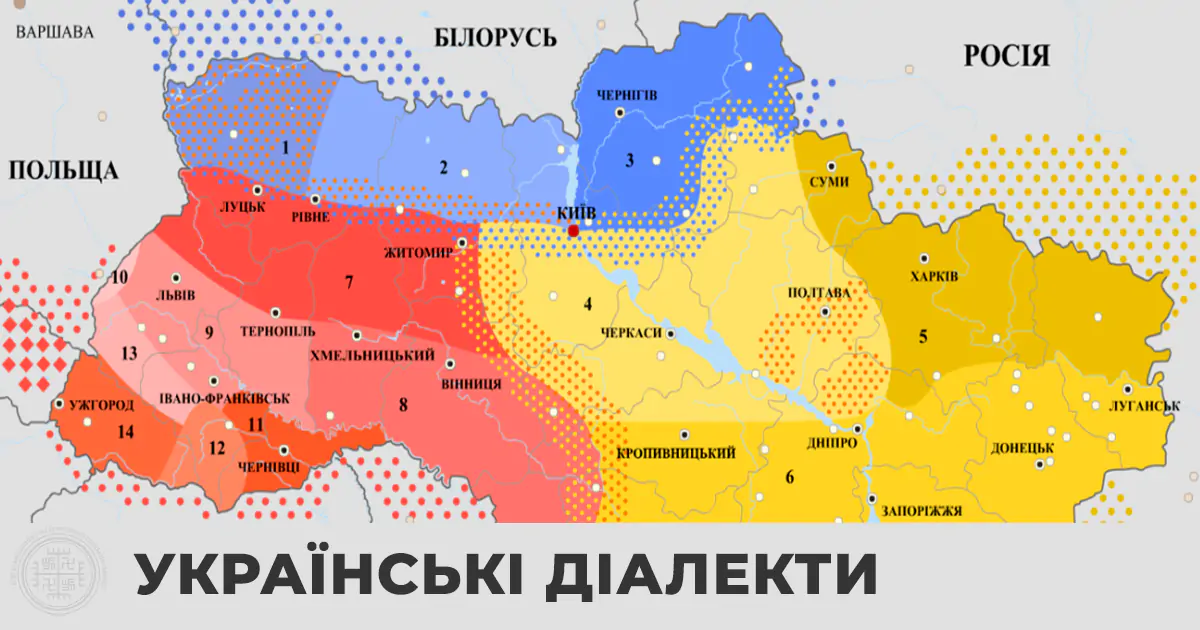
Метою даного дослідження є вивчення сучасного поширення діалектів та рідковживаних слів української мови за допомогою математичних методів.
Основними задачами є:
- Окреслити регіони вживання певних слів. Провести межі між місцевостями, де по-різному називають одні і ті ж поняття чи речі.
- Використовуючи залежність між роком народження і рівнем вживання, оцінити коли зникне з ужитку те чи інше слово в різних місцевостях.
- Дослідити автокореляції рівня вживання слів за віком респондентів і за географічною відстанню між ними. Визначити на яких просторових масштабах існує зв'язок між людьми беручи до уваги їхню лексику.
- Порівняти лексику окремих регіонів та населених пунктів,
- Перевірити чи теперішня мова відображає історичні межі минулих століть.
Дані
Джерелом первинної інформації є дані опитування щодо вживаності більше 400 вибраних слів. Запропоновано таку градацію рівнів вживання кожного слова:
- 5 - активно вживаю тільки такий варіант слова;
- 4 - вживаю час від часу, або на рівні з іншим аналогом;
- 3 - вкрай рідко вживаю;
- 2 - знаю, але ніколи не вживаю;
- 1 - ніколи не чув цього слова.
Кожен респондент також вказував рік свого народження та населений пункт в якому проживав до закінчення школи. Вважаємо, що саме до закінчення школи формується основна лексика. В період з грудня 2011 до лютого 2016 в опитуванні взяли участь 2399 особи. Розподіл кількості респондентів за роками народження приведено на рисунку нижче.
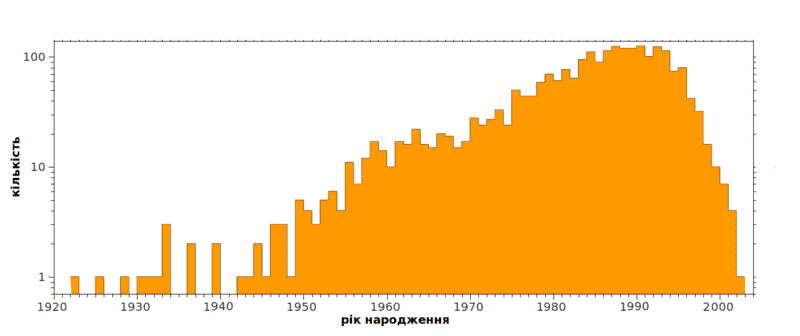
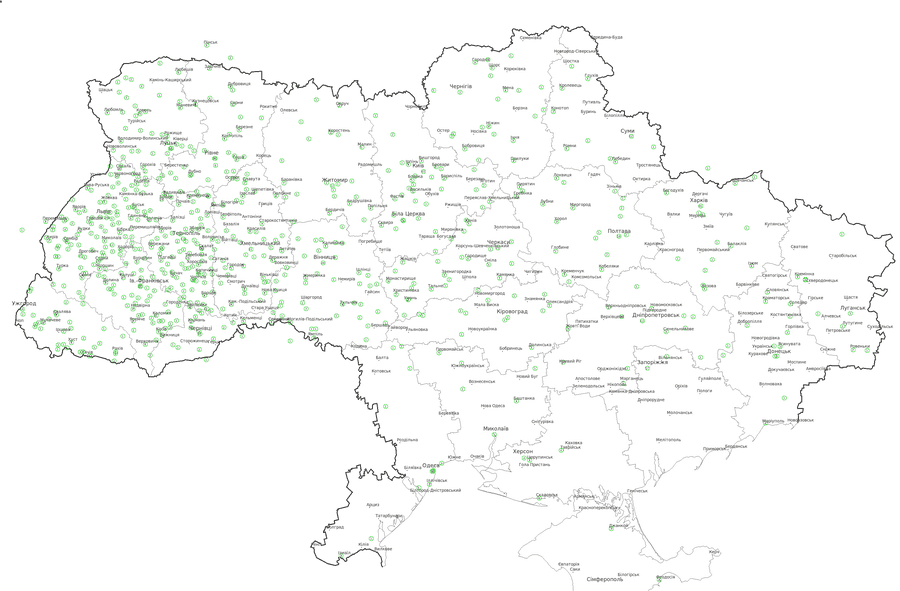
Найстарший респондент 1922 року народження, а наймолодший 2002, середній рік народження 1983, медіанний 1986. Карта нижче показує географію отриманих анкет. Числа в зелених кругах відповідають кількості респондентів з даного місця. Числа в зелених кругах показують кількість респондентів з даного місця. Кілька респондентів є з Польщі, Білорусі, Росії, Румунії і Молдови.
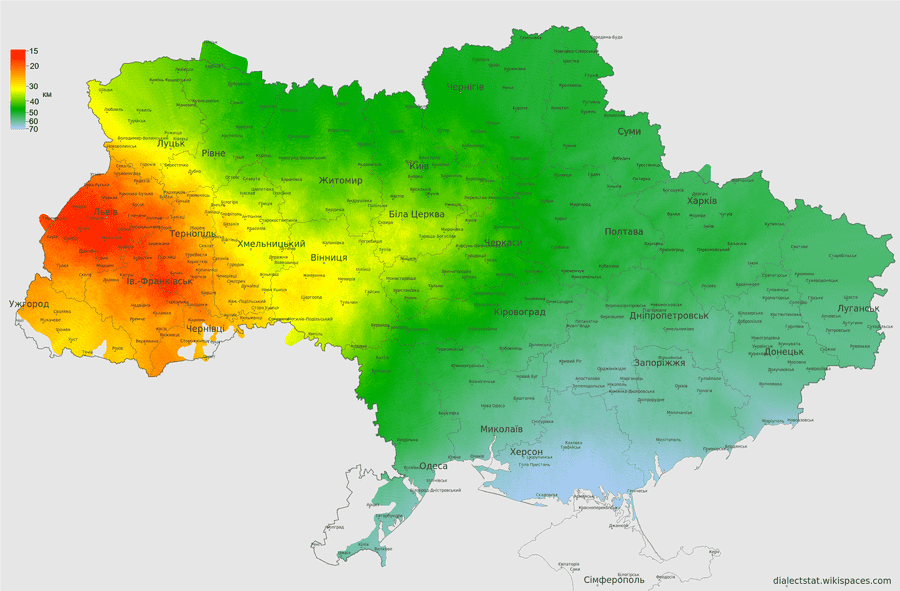
Враховуючи дуже не однорідний географічний розподіл респондентів ми ввели типову відстань d0 респондентами для кожної точки:
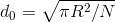
де N - кількість населених пунктів з яких отримано принаймні одну відповідь, в радіусі R навколо даної точки. Для компромісу між достатньою статистикою і детальністю ми брали коло такого радіусу, щоб воно охоплювало біля 40 респондентів. При цьому враховувалася лише площа області дослідження. Карта нижче показує розподіл типової відстані між респондентами. Сірі зони не були взяті до уваги, оскільки вживання українських діалектів там дуже низьке.
Карти рівня використання
Географічний розподіл респондентів є дуже нерівномірним тому для побудови згладжених карт рівнів вживання ми використали середнє зважене для кожного пікселя (x,y). Для вагових коефіцієнтів ми вибрали функцію Гауса exp(-(di/d0)2). Тут di - відстань в км. від даної точки на карті до i-го респондента, d0 - типова відстань між н.п. з карти вище. В даному випадку, вагові коефіцієнти швидко спадають з відстанню, насправді значний вплив на колір даного пікселя мають лише найближчі респонденти. Але формально ми враховуємо вплив всіх респондентів. Отже, для побудови згладжених карт розподілу рівня вживання Bj(x,y) j-го слова в певній точці (x,y) на карті, ми враховували рівні bi,j від кожного i-го респондента:
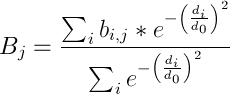
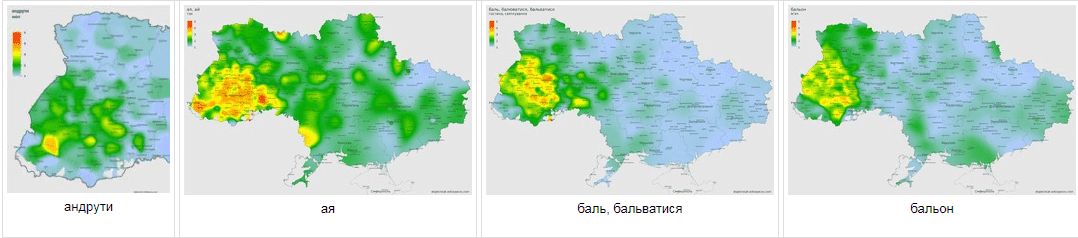
Для великих міст притаманні активні міграційні впливи, тому такі міста не можуть відображати коректно лексику навколо себе. Тому для багатьох міст, як правило обласних центрів, ми обчислювали рівні вживання окремо. А саме як середньоарифметичну величину по респондентах з даного міста. Такі міста на картах ми позначаємо як круги одного кольору і площею, що дорівнює офіційній площі міста. Нижче подані карти розподілів рівнів вживання для охоплених слів.
Кластеризація
На основі ареалів розповсюдження слів ми поділили їх на групи. Як відстань між j-вим and k-тим словом використано відстань Пірсона:
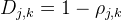
де коефіцієнт кореляції Пірсона між Bj and Bk популяцією:
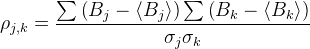
Сумування відбувається по всіх пікселях даної карти, σ - стандартне відхилення B. Відстань Пірсона змінюється в межах [0, 2]. Прикладом двох близьких з малою відстанню між ними є "кльош" і "ромбамбар" D=0.08. Вони мають дуже подібний ареал розповсюдження. Очевидно, що їхнє походження чи прихід відбувся в одну епоху:
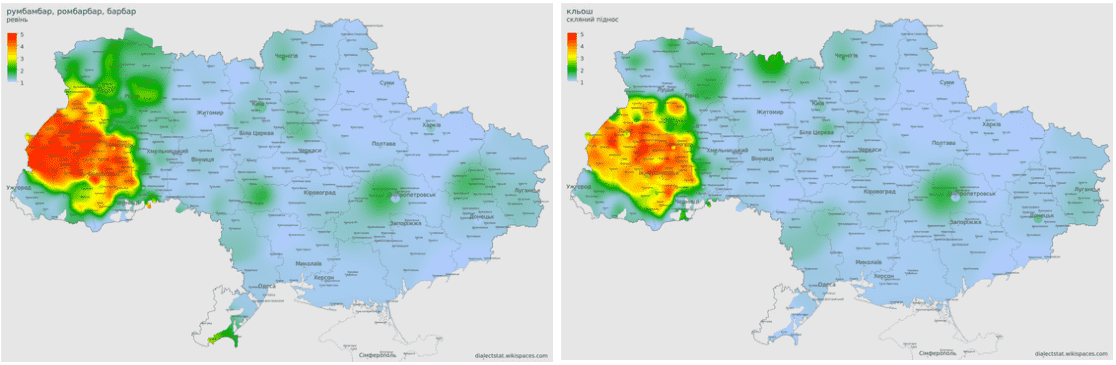
Приклад пари слів з великою відстаню між ними ~2 тремпель і леквар:На основі інформації про відстані Пірсона попарно між всіма словами ми кластеризували їх і створили наступну дендограму:
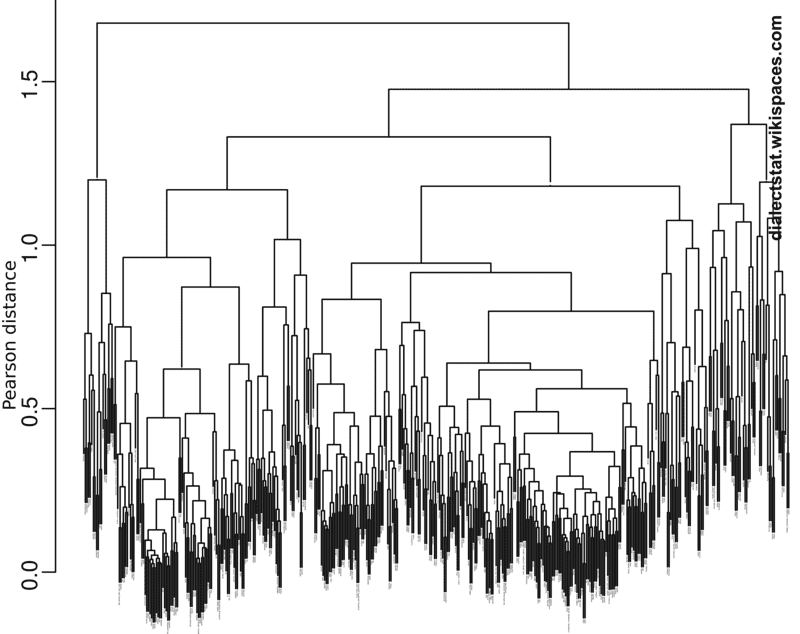
На основі інформації про відстані Пірсона між всіма парами слів ми кластерували їх і створили дендограму:
Різноманітність назв
Існує низка понять та речей, які по різному називають в різних місцевостях. Для виокремлення таких регіонів де панує певна назва ми використали попередні згладженні карти рівнів вживання. Для кожної точки на карті ми вибрали те слово яке має там максимальний рівень вживання. Звичайно, це не виключає, що в даному місці паралельно вживають інші варіанти для позначення даного поняття чи речі. Нижче приведені карти поширення різних варіантів діалектних відповідників слів ВЕЛОСИПЕД, ЛЕЛЕКА, КАРТОПЛЯ, ДЕРУНИ, СКОВОРОДА, ДЕКО, ГАНЧІРКА ТА ГОРИЩЕ.
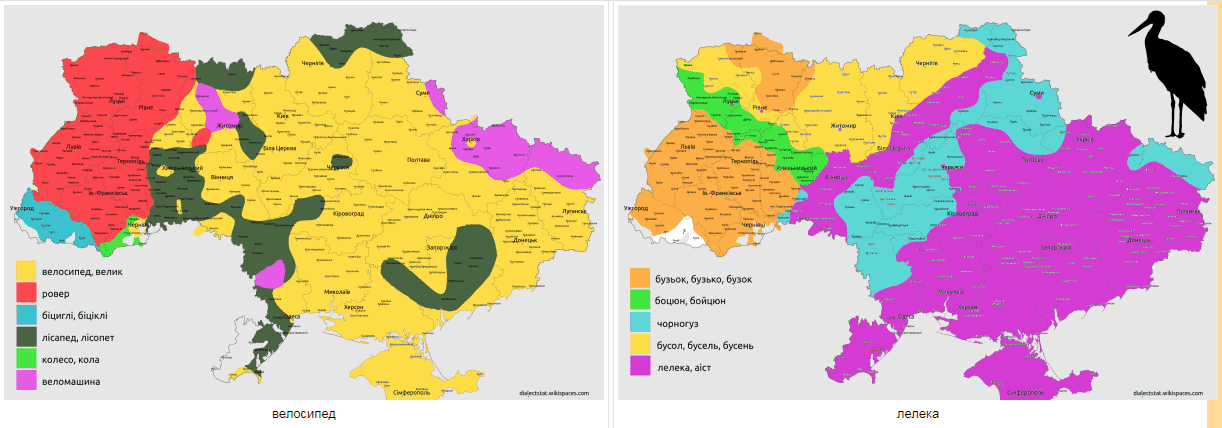
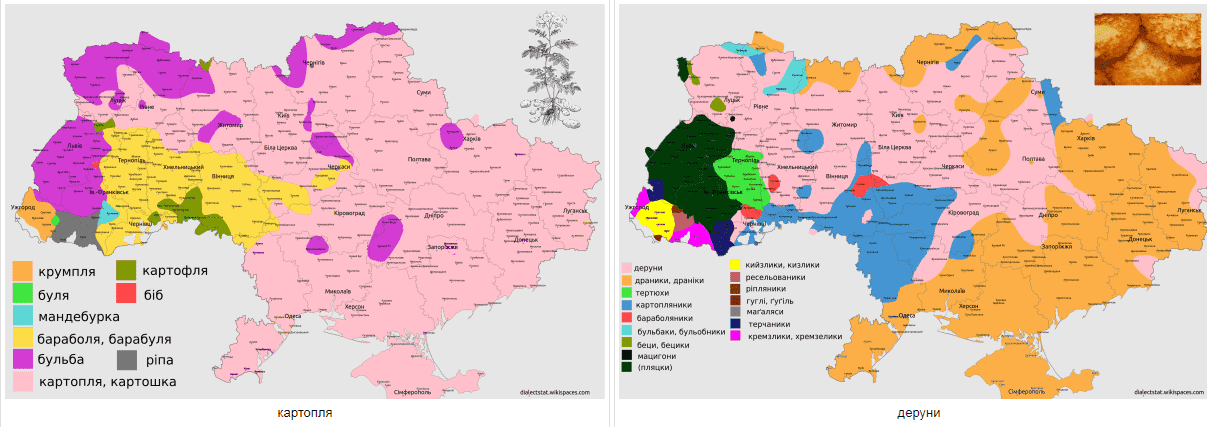
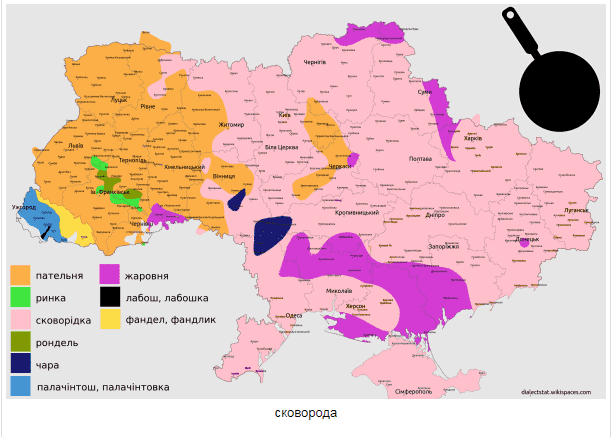
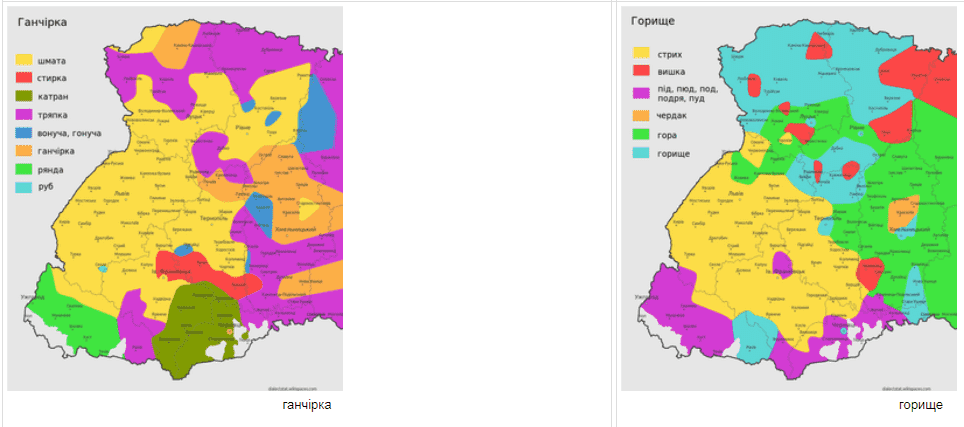
Дане дослідження входить в проект Dialectstat, котрий є приватною ініціативою автора -
Андрія Елиїва LinkedIn.
- Культурно-історичний портал "Спадщина Предків"






